Crawling and Indexing: How Do They Work?
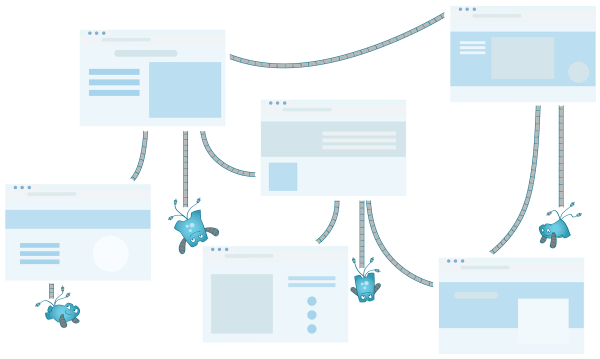
The primary goal of search engines is to scour the internet for all existing pages (about and pick which ones could provide web users the most valuable, trustworthy information. When doing so, they need to do it quickly and efficiently. However, this isn’t easy. The internet is a massive collection of web pages; that is why gathering all the information in a short period is among a search engine’s goals. In this article, we will talk about how crawling and indexing work and the relevance of internal linking in crawling.
Get yourself ready for the useful things to know that will effectively help you with your website.

Getting a Deeper Understanding of Crawling
Currently, there are trillions of live pages on the internet, and they’re growing by numbers each day. So, crawling all of them would take a lot of time. Crawling is the process of finding all the links in a page, following each of them, and repeating the process repeatedly to look for other new pages.
Marketers and professionals refer to web crawlers by different names: robots, spiders, search engine bots, bots, or spider bots. The primary reason web crawlers are classified as robots is that they are programmed to perform a series of assigned tasks—nothing more, nothing less.
As mentioned earlier, crawlers only have to travel from link to link and gather all the information they can get on a particular web page.
You might be wondering, “how does crawling start?”
Search engines have a list of trusted websites they use as a seed list. These pages have links that link to other websites. Aside from the seed list, they also use previously crawled websites as well as the sitemaps that website owners have submitted.
Crawling actually never stops. As long as there are links and web pages, crawling will be present. Crawling is a very important task for search engines since it allows them to find new pages with newer information and grade the content.
Once a piece of content has been graded, search engines will segregate which pages are helpful and which are not. Pages that don’t meet the standards that search engines set will usually be placed at the lower parts of search engine results pages (SERPs). On the other hand, the most valuable pages will show up on the first page of search engines.
Since search engines value the time of their users, they don’t want to show them websites that won’t give any value.
Search Engine Results Pages
Search engine results pages, also known as SERPs, are where the best websites show up. It will usually look at a couple of factors when picking which sites to feature on the first page of SERPs. Here are the important factors you need to keep in mind:
Popularity
Search engines like Google prioritize websites that are often linked to by different websites. Getting linked to by other websites is similar to having “votes” because your content is worthy of being shared with other people.
A link to your site can also mean that a website trusts your content because it contains credible and updated information.
Quality
Not all pieces of content on the internet are created equal. The quality of content depends on the information placed in it, the structure, tone, and many other factors. Search engines employ a sophisticated algorithm that determines a content’s quality.
E-A-T is the concept that search engines use to grade content. It stands for expertise, authoritativeness, and trustworthiness. So, if a search engine like Google sees that your content possesses these three, it will surely put your pages at a higher rank.
Freshness of Information
Since search engines can determine the freshness of information in a piece of content, they often look for the ones with updated data. A search engine will put your website on top of the ranks if you constantly update the information on your content and make sure that they are accurate and from authoritative websites.
Frequency of Publication
Aside from the three, search engines also prioritize websites that always provide web users with a ton of high-quality content. When a site posts high-quality content frequently and the amount of organic traffic is also high, search engines will consider that site a source of new and exciting information.
When this happens, that site might be displayed on top of SERPs.
Crawl Budget
The simplest definition for crawl budget is that it is the number of pages that a search engine will crawl and index on a website over a certain amount of time. There are a lot of factors that affect the budget allotted to a site. The most common factors are:
- Size of pages
- Quality of pages
- Updates made on the pages
- The popularity of the site
- Speed of the website
For marketers, the crawl budget is a very important aspect of crawling. When this is wasted, the overall ranking of a site can be affected negatively. This means that the pages will be crawled less often, resulting in lower rankings on SERPs.
A search engine like Google picks which websites to crawl frequently; however, it doesn’t allow any website to pay just to get crawled more often. There are cases where a website owner doesn’t want a search engine to crawl over a particular webpage.
In this case, a robots.txt file is used. Using the robots.txt file should only be used by experts since it can unintentionally isolate all pages on a website from Google.
With a disorganized website structure, your crawl budget will be wasted! The Internal Link Juicer is a plugin that can help you create a web of interlinked pages that search engine bots can easily understand. This way, they won’t have a hard time knowing what your site is all about.

Indexing: What is it?
A lot of people think that crawling and indexing are a part of just one process. However, that is not the case. The two are different processes, and each has its purpose. We have talked about crawling earlier, so we are now going to help you understand what indexing is and how it works.
Indexing is the process of storing and organizing all the information placed on a web page. When a crawl bot enters a page, it renders the code of that particular page, and it catalogs everything it renders. It includes content, links, and metadata on the page.
The indexing process isn’t an easy task for search engines since it requires massive storage. Not just data storage. Rendering trillions of web pages will need a considerable amount of computing resources.
Rendering
It is the process of understanding languages like HTML, CSS, and Javascript and building a replica of what web users see on their browsers. The amount of time associated with rendering depends on the size of the site and the code used to create it.
What is Indexed and Organized on a Website?
- Detailed information on what the content is about and the relevance of every web page.
- A map that includes all the pages that every page links to
- Anchor texts of all links
- Relevant information about links (if they are advertisements, their location on the page, etc.)

Internal Links and Crawling
Internal links are links in your content that lead your web users to another location in your website. These links can be in the form of images, videos, text, or other elements that can be found on a website.
When a bot arrives at your website, they collect all the information and use the internal links on the page to look for other existing pages on the domain. Without internal links, it will be difficult for search engine bots to crawl all the pages on your site.
When this happens, it is possible that your pages won’t be crawled and indexed. It means that your pages might not show up on search engine results pages. Pages that don’t show up on SERPs can have a lower online presence, and the organic traffic it receives will also be significantly lower compared to the pages within the same site that show up on SERPs.
However, if many people know the exact URL of that page, then it may still receive a lot of organic traffic.
When placing internal links in your content, you help search engines understand your site structure and, at the same time, make it easier for your visitors to navigate your web pages. It’s like hitting two birds with one stone.
Crawling and Indexing: Your Key to More Online Visibility
Crawling and indexing all the pages on the internet is a challenging task for search engines. That is why when you incorporate internal links into your content and create an organized internal linking structure, you help web crawlers do their job a lot easier. While helping them, you also reap the benefits of internal linking itself. You get to maximize the allotted crawl budget for your website, meaning that most, if not all of your pages, will be crawled and indexed by the search engine crawl bot.
A well-planned internal linking structure and organized internal links on your site can be achieved by using internal link managing tools. Visit Internal Link Juicer today to grab our premium plugin.